How to Train Neural Field Representations: A Comprehensive Study and Benchmark
-
Go to last slide Go to next slide
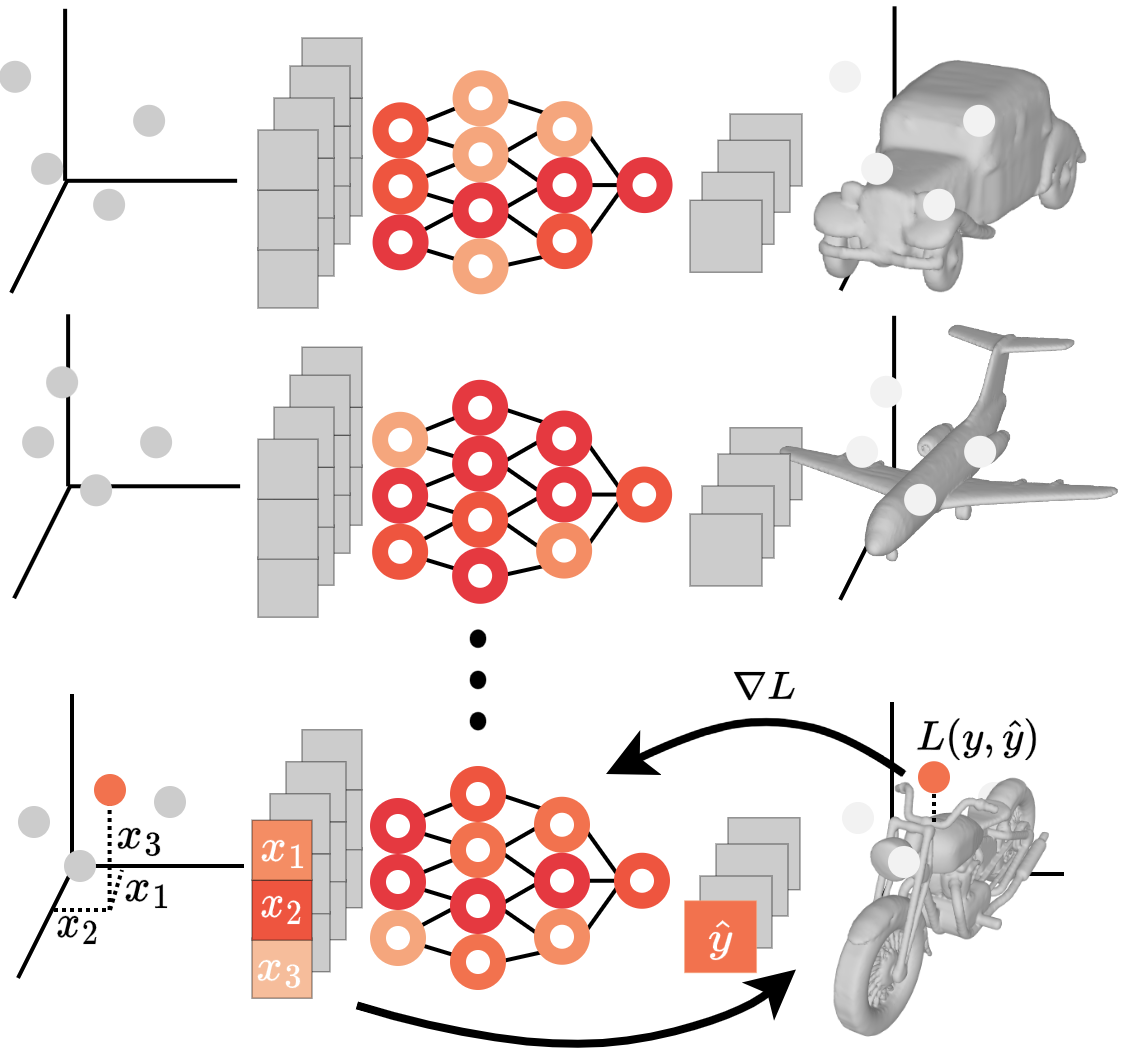
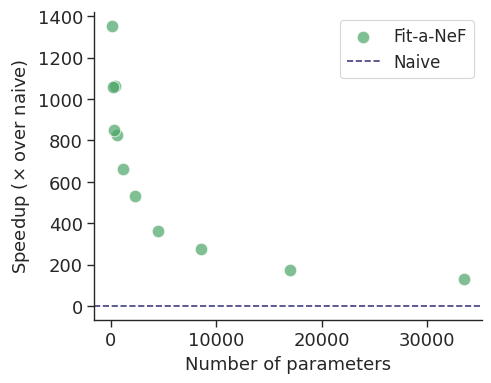 To investigate the use of Neural Fields (NeFs) as representations, we propose Fit-a-NeF, a JAX-based library for efficient parallelized fitting of NeFs to datasets of signals, obtaining a $100{-}1,300 \times$ speed-up. Owing to this efficiency, we are able to uncover the impact of NeF hyperparameter choices on their usability as representations -- evaluated in downstream classification.
To investigate the use of Neural Fields (NeFs) as representations, we propose Fit-a-NeF, a JAX-based library for efficient parallelized fitting of NeFs to datasets of signals, obtaining a $100{-}1,300 \times$ speed-up. Owing to this efficiency, we are able to uncover the impact of NeF hyperparameter choices on their usability as representations -- evaluated in downstream classification. -
Go to previous slide Go to next slide
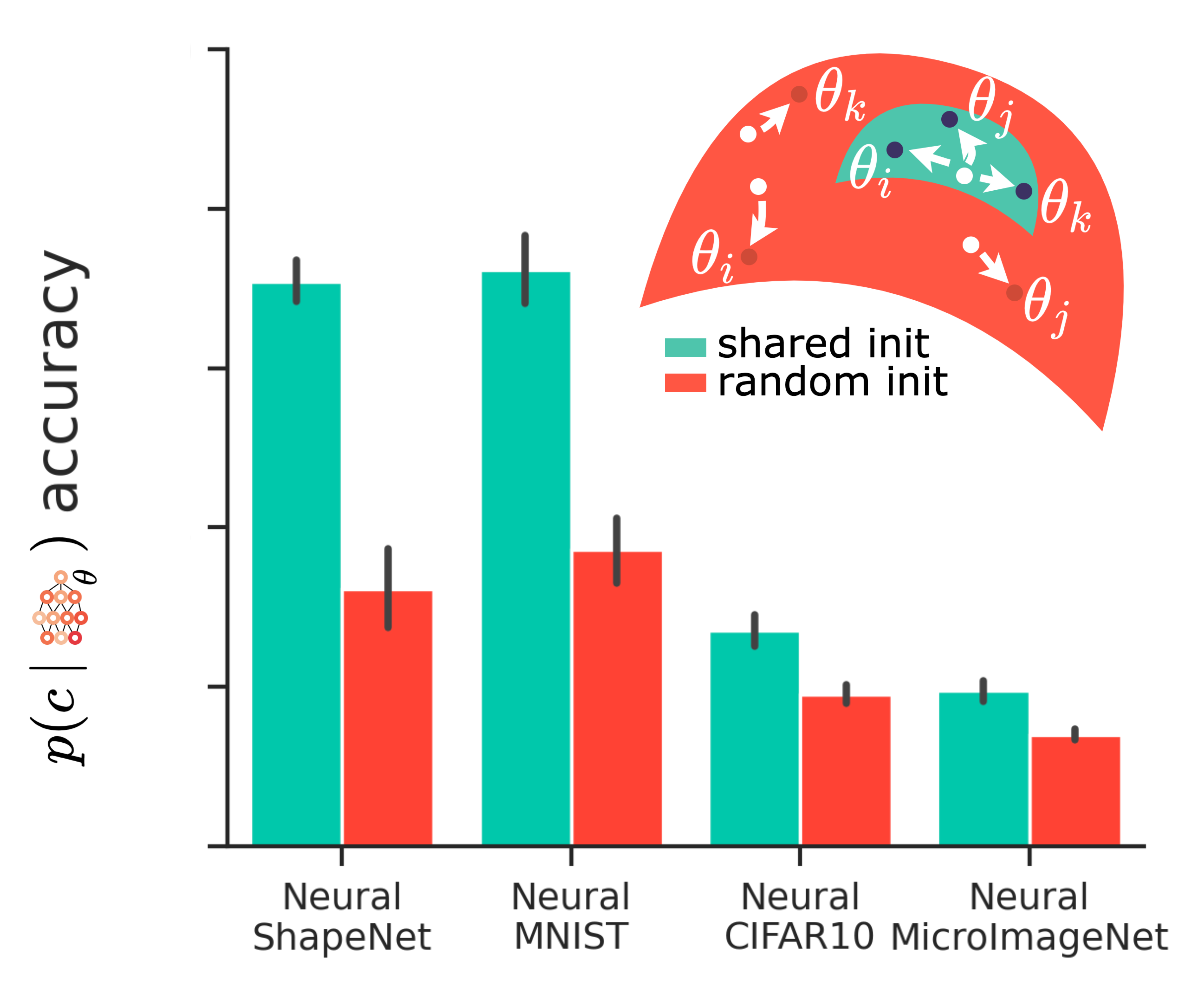
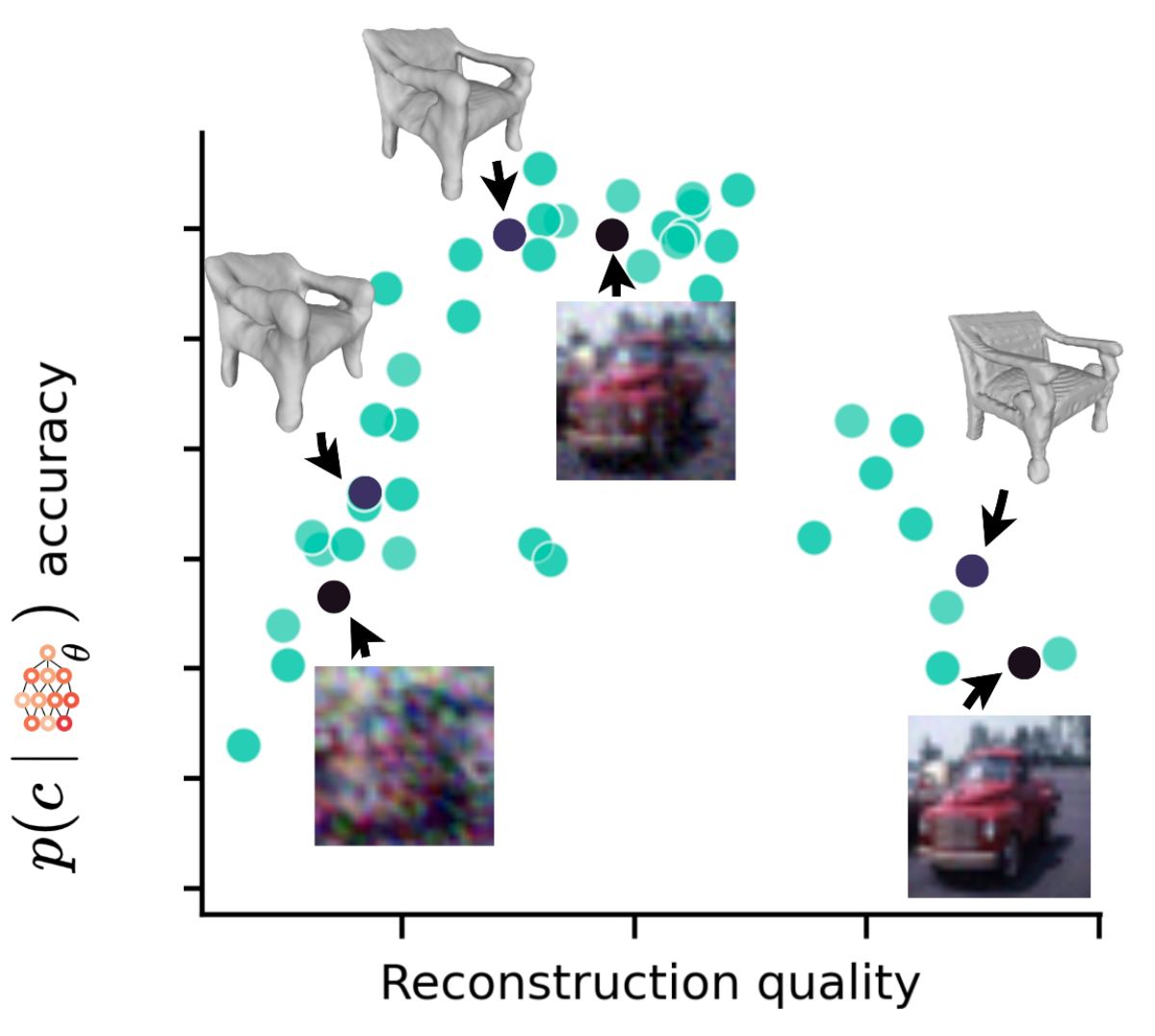 We obtain two important insights with these experiments on downstream classification. First (left), it is vital to group NeFs in parameter-space, which we propose to enforce by sharing their network initializations. Second (right), improved reconstruction quality does not necessarily result in improved representation quality, implying an optimal combination of NeF expressivity and optimization for learning on NeFs.
We obtain two important insights with these experiments on downstream classification. First (left), it is vital to group NeFs in parameter-space, which we propose to enforce by sharing their network initializations. Second (right), improved reconstruction quality does not necessarily result in improved representation quality, implying an optimal combination of NeF expressivity and optimization for learning on NeFs. -
Go to previous slide Go to first slide
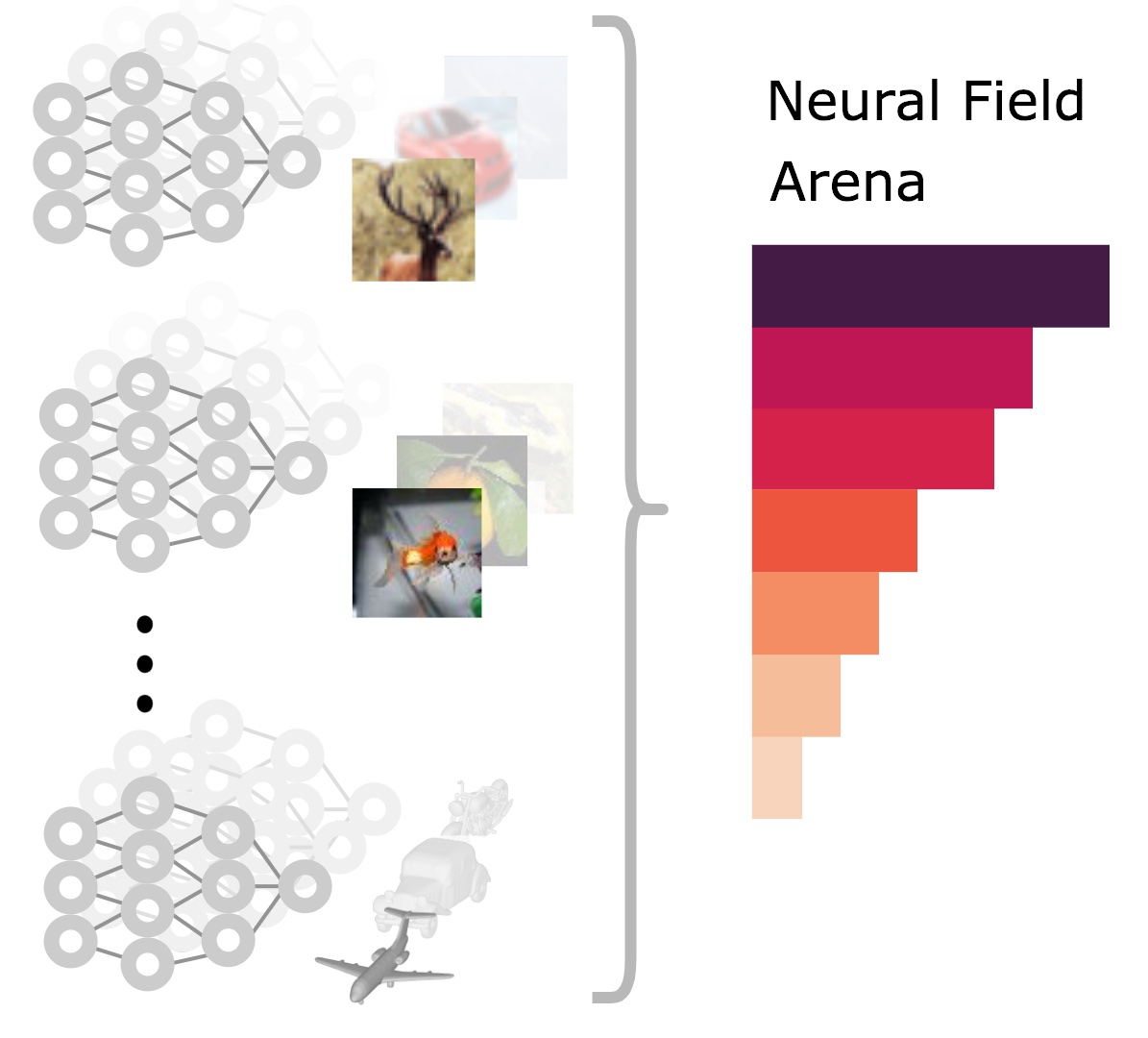 Incorporating these insights, we create a suite of NeF-based variants of classical CV datasets. We bundle these Neural Datasets into a benchmark for learning on Neural Fields -- which we name Neural Field Arena -- hoping to enable standardized comparison in order to promote further research into this field.
Incorporating these insights, we create a suite of NeF-based variants of classical CV datasets. We bundle these Neural Datasets into a benchmark for learning on Neural Fields -- which we name Neural Field Arena -- hoping to enable standardized comparison in order to promote further research into this field.
Introduction
Neural Fields (NeFs) are a class of coordinate-based neural networks that are trained to reconstruct discretely sampled input signals.
We created Fit-a-NeF, a JAX-based library for efficient parallelized
fitting of NeFs to datasets of signals, to enable us to investigate the use of NeFs as downstream representations.
With the insights gained, we created a benchmark for learning on NeFs: Neural Field
Arena. On this website you can find an overview of the main results and instructions for using the library and benchmark.
For more details on implementation and design choices, please refer to our paper and the GitHub repositories for Fit-a-NeF and Neural Field Arena.
Experiments and results
We performed a series of experiments to investigate the use of NeFs as representations.
After training NeFs on a variety of datasets, we evaluated their performance in downstream classification.
In these experiments, we vary the NeF hyperparameters -- such as hidden dimension and number of training steps --
and evaluated their impact on the NeF's usability as a representation. We also investigated the impact of
the reconstruction quality of the NeF on its usability as a representation.

Reconstruction quality. For some context, from left to right, samples
of NeFs with increasing reconstruction quality. The right-most column shows the ground
truth used for fitting.
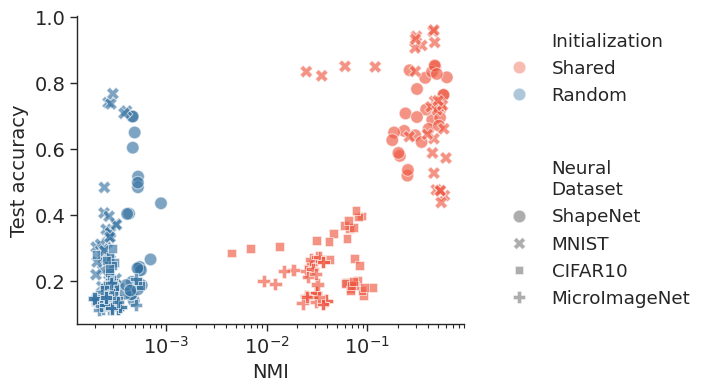
Shared initialization. Instead of randomly initializing each NeF separately, starting from the same shared
initialization results in a grouping of NeFs in parameter-space, (left) significantly increasing downstream accuracy.
(right) Results of the test accuracy ($\uparrow$) vs NMI ($\uparrow$) using different initialization on 220 Neural
Datasets created using different hidden dimensions and the number of steps. Shared initialization leads to semantically structured NeF representation and,
generally to better performance.
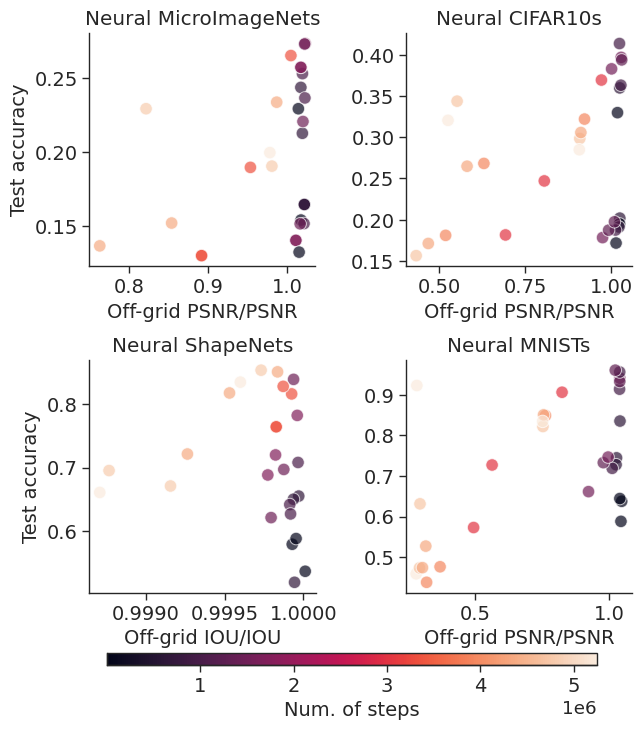
Reconstruction quality and representation quality. We fit 220
datasets of NeFs using different hidden dimensions and the number of steps while keeping the same shared initialization.
We find that the ratio of off-grid reconstruction quality and in-grid reconstruction quality can be used to form a
heuristic that correlates with high test accuracy
Neural Field Arena
The Neural Field Arena is a benchmark for learning on Neural Fields. It consists of a suite of Neural Datasets, which are
Neural Field variants of classical CV datasets. Currently, the benchmark covers classification tasks on 4 datasets:
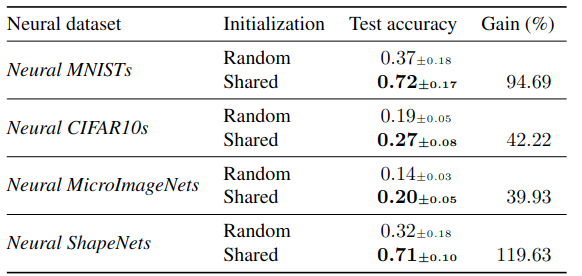
Neural MNIST, Neural CIFAR10, Neural MicroImageNet, Neural ShapeNet, but we are working on expanding the benchmark to include more datasets and tasks.
All datasets are obtained using the Fit-a-NeF library. Find the currently recorded state-of-the-art results below.
Neural Dataset
Test accuracy
Downloading and using Neural Field Arena
We created a PyTorch-based dataloader for the Neural Field Arena. For instructions on downloading and using
the Neural Field Arena, please refer to the GitHub repository.
Citing
In case you would like to refer to the Neural Field Arena in your work, you can cite it as follows:
@misc{papa2023train,
title={How to Train Neural Field Representations: A Comprehensive Study and Benchmark},
author={Samuele Papa and Riccardo Valperga and David Knigge and Miltiadis Kofinas and Phillip Lippe and Jan-Jakob Sonke and Efstratios Gavves},
year={2023},
eprint={2312.10531},
archivePrefix={arXiv},
primaryClass={cs.CV}
}References